Cassandra anti-pattern: Logged batches
I've previously blogged about other anti-patterns:
Short answer: consistent denormalisation. In most cases you won't want to use them, they are a performance hit. However for some tables where you have denormalised you can decide to make sure that both statements succeed. Lets go back to our customer event table from the previous post but also add a customer events by staff id table:
Logged batches are rarely to be used, they add complexity if you try to read at SERIAL after failure and they are a performance hit. If you are going to use them it is in the odd situation where you can't handle inconsistencies between tables. They allow you to guarantee the updates will eventually happen, they do not however offer isolation i.e a client can see part of the batch before it is finished.
- Distributed joins
- Unlogged batches
This post is similar to the unlogged batches post but is instead about logged batches.
We'll again go through an example Java application.
The good news is that the common misuse is virtually the same as the last article on unlogged batches, so you know what not to do. The bad news is if you do happen to misuse them it is even worse!
Let's see why. Logged batches are used to ensure that all the statements will eventually succeed. Cassandra achieves this by first writing all the statements to a batch log. That batch log is replicated to two other nodes in case the coordinator fails. If the coordinator fails then another replica for the batch log will take over.
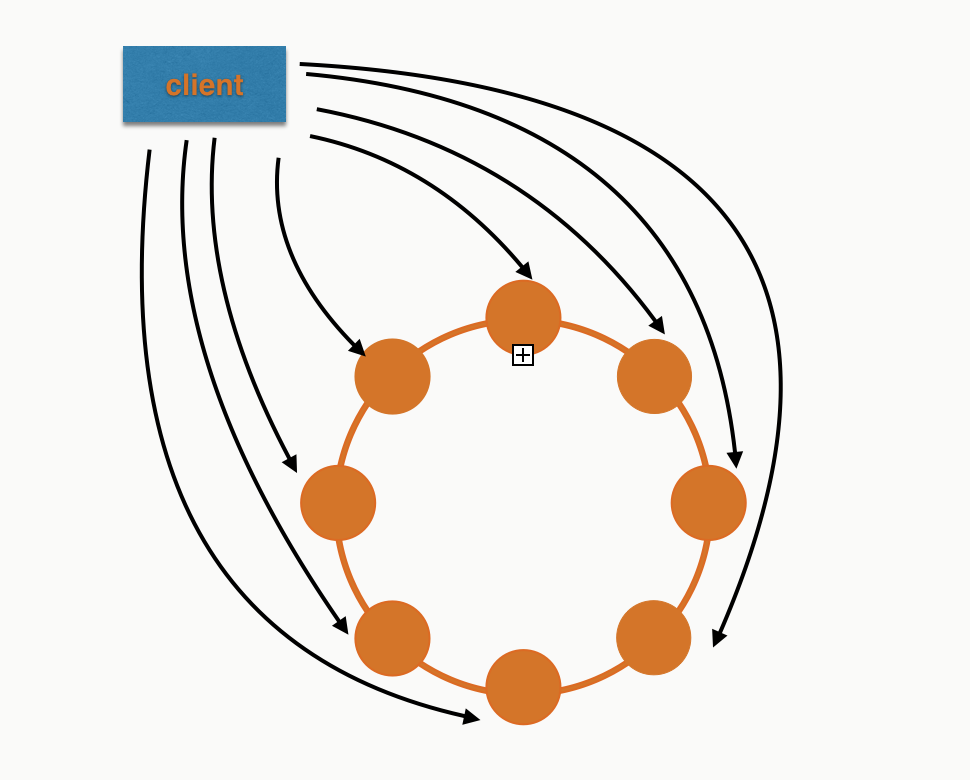
Now that sounds like a lot of work. So if you try to use logged batches as a performance improvement then you'll be very disappointed! For a logged batch with 8 insert statements (equally distributed) in a 8 node cluster it will look something like this:

The coordinator has to do a lot more work than any other node in the cluster. Where if we were to just do them as regular inserts we'd be looking like this:
A nice even workload.
The good news is that the common misuse is virtually the same as the last article on unlogged batches, so you know what not to do. The bad news is if you do happen to misuse them it is even worse!
Let's see why. Logged batches are used to ensure that all the statements will eventually succeed. Cassandra achieves this by first writing all the statements to a batch log. That batch log is replicated to two other nodes in case the coordinator fails. If the coordinator fails then another replica for the batch log will take over.
Now that sounds like a lot of work. So if you try to use logged batches as a performance improvement then you'll be very disappointed! For a logged batch with 8 insert statements (equally distributed) in a 8 node cluster it will look something like this:
The coordinator has to do a lot more work than any other node in the cluster. Where if we were to just do them as regular inserts we'd be looking like this:
A nice even workload.
So when would you want to use logged batches?
Short answer: consistent denormalisation. In most cases you won't want to use them, they are a performance hit. However for some tables where you have denormalised you can decide to make sure that both statements succeed. Lets go back to our customer event table from the previous post but also add a customer events by staff id table:
We could insert into this table in a logged batch to ensure that we don't end up with events in one table and not
the other. The code for this would look like this:
This would mean both inserts would end up in the batch log and be guaranteed to eventually succeed.
The downside is this adds more work and complexity to our write operations. Logged batches have two opportunities
to fail:
- When writing to the batch log
- When applying the actual statements
Let's forget about reads as they aren't destructive and concentrate on writes. If the first phase fails
Cassandra returns a WriteTimeoutException with write type of BATCH_LOG. This you'll need to retry if you want
your inserts to take place.
If the second phase fails you'll get a WriteTimeoutException with the write type of BATCH. This means it made it to
the batch log so that they will get replayed eventually. If you definitely need to read the writes you would read at
SERIAL, meaning any committed batches would be replayed first.
Conclusion
Logged batches are rarely to be used, they add complexity if you try to read at SERIAL after failure and they are a performance hit. If you are going to use them it is in the odd situation where you can't handle inconsistencies between tables. They allow you to guarantee the updates will eventually happen, they do not however offer isolation i.e a client can see part of the batch before it is finished.