Cassandra anti-pattern: Misuse of unlogged batches
This is my second post in a series about Cassandra anti-patterns,
here's the first on distributed joins. This post will be on unlogged batches and the next one on logged batches.
Batches are often misunderstood in Cassandra. They will rarely increase performance, that is not their purpose. That can come as quite the shock to someone coming from a relational database.
If we were to keep them as normal insert statements and execute them asynchronously we'd get something more like this:
How about if we wanted to implement the following method:
Let's understand why this is the case with some examples. In my last post on Cassandra anti-patterns I gave all the
examples inside CQLSH, however let's write some Java code this time.
We're going to store and retrieve some customer events. Here is the schema:
Here's a simple bit of Java to persist a simple value object representing a customer event, it also creates the
schema and logs the query trace.
We're using a prepared statement to store one customer event at a time. Now let's offer a new interface to batch
insert as we could be taking these of a message queue in bulk.
It might appear naive to just implement this with a loop:
However, apart from the fact we'd be doing this synchronously, this is actually a great idea! Once we made this
async then this would spread our inserts across the whole cluster. If you have a large cluster, this will be what
you want.
However, a lot of people are used to databases where explicit batching is a performance improvement. If you did
this in Cassandra you're very likely to see the performance reduce. You'd end up with some code like this (the code
to build a single bound statement has been extracted out to a helper method):
Looks good right? Surely this means we get to send all our inserts in one go and the database can handle them in
one storage action? Well, put simply, no. Cassandra is a distributed database, no single node can handle this type
of insert even if you had a single replica per partition.
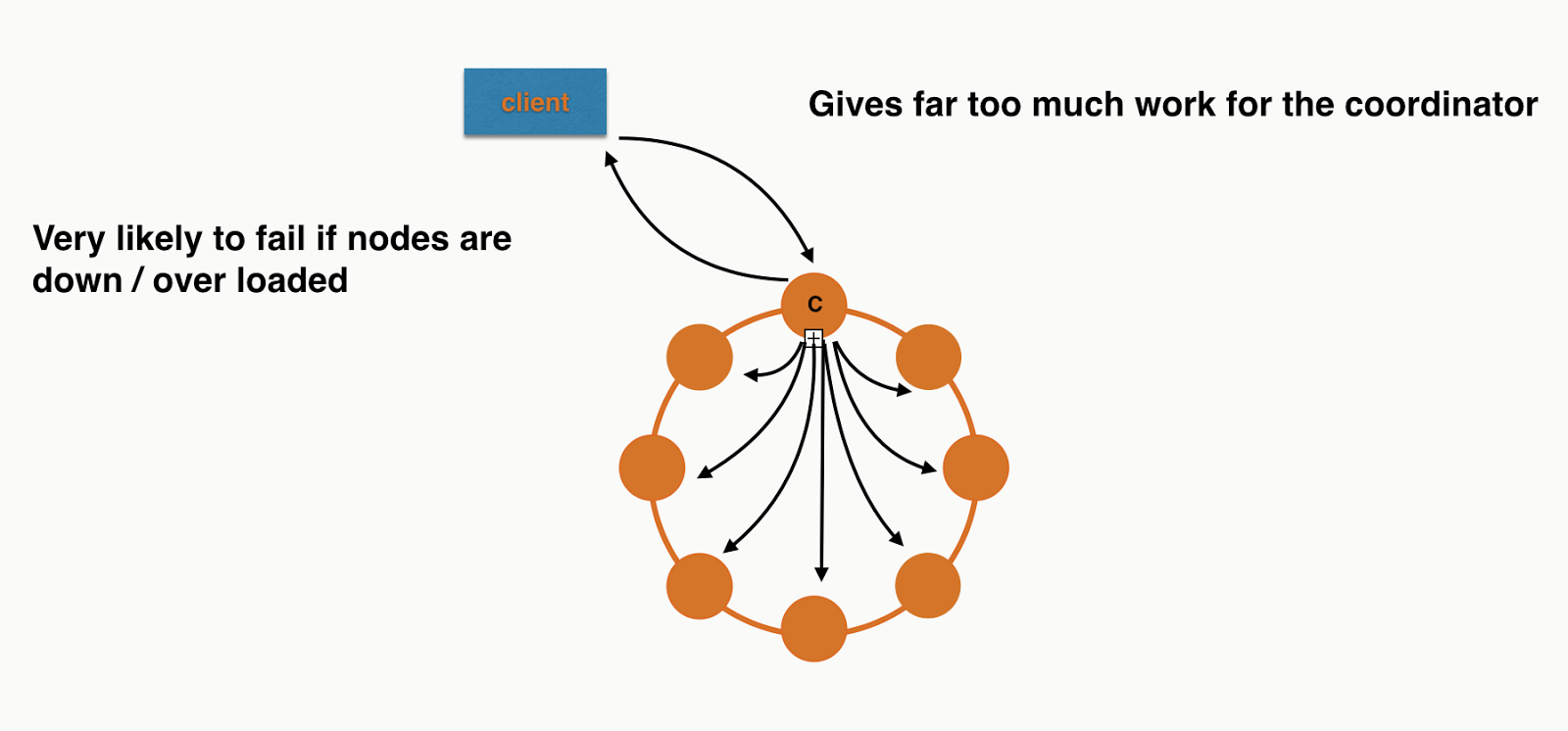
What this is actually doing is putting a huge amount of pressure on a single coordinator. This is because the coordinator needs to forward each individual insert to the correct replicas. You're losing all the benefit of token aware load balancing policy as you're inserting different partitions in a single round trip to the database.
If you were inserting 8 records in a 8 node cluster, assuming even distribution, it would look a bit like this:
What this is actually doing is putting a huge amount of pressure on a single coordinator. This is because the coordinator needs to forward each individual insert to the correct replicas. You're losing all the benefit of token aware load balancing policy as you're inserting different partitions in a single round trip to the database.
If you were inserting 8 records in a 8 node cluster, assuming even distribution, it would look a bit like this:
Each node will have roughly the same work to do at the storage layer but the Coordinator is overwhelmed. I didn't
include all the responses or the replication in the picture as I was getting sick of drawing arrows! If you need
more convincing you can also see this in the trace. The code is checked into Github so you can run it your self. It
only requires a locally running Cassandra cluster.
Back to individual inserts
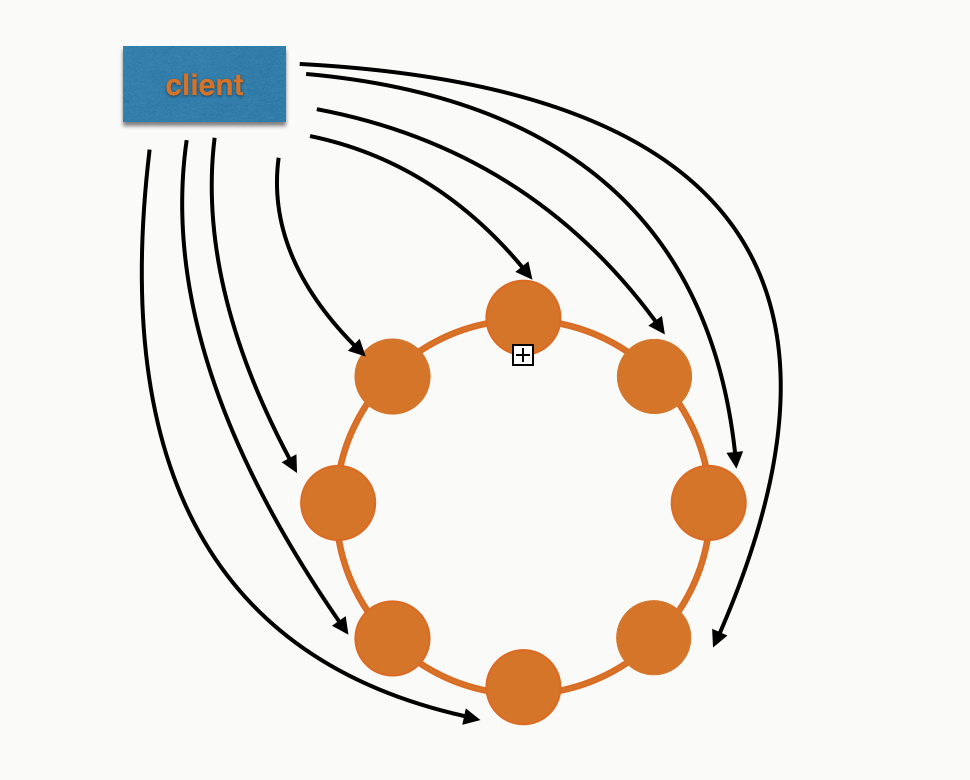
If we were to keep them as normal insert statements and execute them asynchronously we'd get something more like this:
Perfect! Each node has roughly the same work to do. Not so naive after all :)
So when should you use unlogged batches?
How about if we wanted to implement the following method:
Looks similar - what's the difference? Well customer id is the partition key, so this will be no more coordination
work than a single insert and it can be done with a single operation at the storage layer. What does this look like
with orange circles and black arrows?

Simple! Again I've left out replication to make it comparable to the previous diagrams.
Conclusion
Most of the time you don't want to use unlogged batches with Cassandra. The time you should consider it is when you
have multiple inserts/updates for the same partition key. This allows the driver to send the request in a single
message and the server to handle it with a single storage action. If batches contain updates/inserts for multiple
partitions you eventually just overload coordinators and have a higher likelihood of failure.
The code examples are on github here.
The code examples are on github here.