Streaming large payloads over HTTP from Cassandra with a small Heap: Java Driver + RX-Java
Cassandra's normal use case is vast number of small read and write operations distributed equally across the cluster.
However every so often you need to extract a large quantity of data in a single query. For example, say you are storing customer events that you normally query in small slices, however once a day you want to extract all of them for a particular customer. For customers with a lot of events than this could be many hundreds of megabytes of data.
If you want to write a Java application that executes this query against a version of Cassandra prior to 2.0 then you may run into some issues. Let us look at the first one..

Previous versions of Cassandra used to bring all of the rows back to the coordinator before sending them to your application, so if the result is too large for the coordinator's heap it would run out of memory.
Let's say you had just enough memory in the coordinator for the result, then you ran the risk of...


From version 2.0, Cassandra would no longer suffer from the coordinator out of memory. This is because the
coordinator pages the response to the driver and doesn't bring the whole result into memory. However if your
application reads the whole ResultSet into memory then your application running out of memory is still an
issue.
However the DataStax driver's ResultSet pages as well, which works really nicely with Rx-Java and JAX-RS StreamingOutput. Time go get real, let's take the following schema:
And you want to get all the events for a particular customer_id (the partition key). First let's write the DAO:
Let's go through this line by line:
2: Async Execute of the query that will bring back more rows that will fit in memory.
4: Convert the ListenableFuture to an RxJava Observable. The Observable has a really nice callback interface / way to do transformation.
5: As ResultSet implements iterable we can flatMap it to Row!
6: Finally map the Row object to CustomerEvent object to prevent driver knowledge escaping the DAO.
And then let's see the JAX-RS resource class:
Looks complicated but it really isn't, first a little about JAX-RS streaming.
The way JAX-RS works is we are given a StreamingOutput interface which we implement to get a hold of the raw OutputStream. The container e.g Tomcat or Jetty, will call the write method. It is our responsibility to keep the container's thread in that method until we have finished streaming. With that knowledge let's go through the code:
5: Get the Observable<CustomerEvent> from the DAO.
6: Create a CountDownLatch which we'll use to block the container thread.
7: Register a callback to consume all the rows and write them to the output stream,
12: When the rows are finished, close the OutputStream.
16: Countdown the latch to release the container thread on line 33.
26: Each time we get a CustomerEvent, write it to the OutputStream.
33: Await on the latch to keep the container thread blocked.
39: Return the StreamingOutput instance to the container so it can call write.
Given that we're dealing with the rows from Cassandra asynchronously you didn't expect the code to be in order did you? ;)
The full working example is on my GitHub. To test it all I put around 600mb of data in a Cassandra cluster for the same partition. There is a sample class in the test directory to do this.
I then started the application with a MaxHeapSize of 256mb, then used curl to hit the events/stream endpoint:
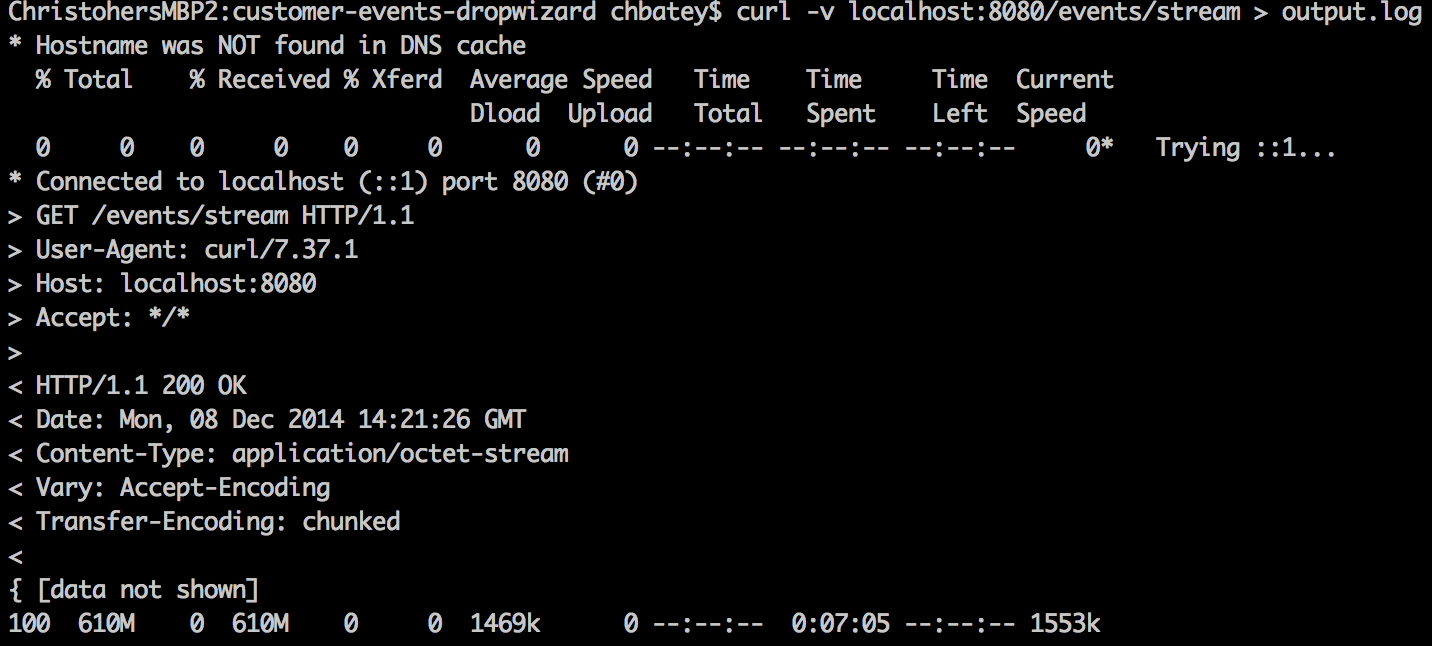
As you can see 610M came back in 7 minutes. The whole time I had VisuamVM attached to the application and the coordinator and monitored the memory usage.
Here's the graph from the application:

For those new to Cassandra and other distributed databases this might not seem that spectacular, but I once wrote a rather large project to do what we can manage here in a few lines. Awesome work by the Apache Cassandra commitors and the DataStax Java driver team.
However every so often you need to extract a large quantity of data in a single query. For example, say you are storing customer events that you normally query in small slices, however once a day you want to extract all of them for a particular customer. For customers with a lot of events than this could be many hundreds of megabytes of data.
If you want to write a Java application that executes this query against a version of Cassandra prior to 2.0 then you may run into some issues. Let us look at the first one..
Coordinator out of memory:
Previous versions of Cassandra used to bring all of the rows back to the coordinator before sending them to your application, so if the result is too large for the coordinator's heap it would run out of memory.
Let's say you had just enough memory in the coordinator for the result, then you ran the risk of...
Application out of memory:
To get around this you had to implement your own paging, where you split the query into many small queries and
processed them in batches. This can be achieved by limiting the results and issuing the next query after the last
result of the previous query.
If your application was streaming the results over HTTP then the architecture could look something like this:
Here we place some kind of queue, say an ArrayBlockingQueue if using Java, between the thread executing the queries
and the thread streaming it out over HTTP. If the queue fills up the DAO thread is blocked, meaning that it won't
bring any more rows from Cassandra. If the DAO gets behind the WEB thread (perhaps a tomcat thread) blocks waiting
to get more rows out of the queue. This works very nicely with the JAX-RS StreamingOutput.
This all sounds like a lot of hard work...
This all sounds like a lot of hard work...
The 2.0+ solution
However the DataStax driver's ResultSet pages as well, which works really nicely with Rx-Java and JAX-RS StreamingOutput. Time go get real, let's take the following schema:
Let's go through this line by line:
2: Async Execute of the query that will bring back more rows that will fit in memory.
4: Convert the ListenableFuture to an RxJava Observable. The Observable has a really nice callback interface / way to do transformation.
5: As ResultSet implements iterable we can flatMap it to Row!
6: Finally map the Row object to CustomerEvent object to prevent driver knowledge escaping the DAO.
And then let's see the JAX-RS resource class:
Looks complicated but it really isn't, first a little about JAX-RS streaming.
The way JAX-RS works is we are given a StreamingOutput interface which we implement to get a hold of the raw OutputStream. The container e.g Tomcat or Jetty, will call the write method. It is our responsibility to keep the container's thread in that method until we have finished streaming. With that knowledge let's go through the code:
5: Get the Observable<CustomerEvent> from the DAO.
6: Create a CountDownLatch which we'll use to block the container thread.
7: Register a callback to consume all the rows and write them to the output stream,
12: When the rows are finished, close the OutputStream.
16: Countdown the latch to release the container thread on line 33.
26: Each time we get a CustomerEvent, write it to the OutputStream.
33: Await on the latch to keep the container thread blocked.
39: Return the StreamingOutput instance to the container so it can call write.
Given that we're dealing with the rows from Cassandra asynchronously you didn't expect the code to be in order did you? ;)
The full working example is on my GitHub. To test it all I put around 600mb of data in a Cassandra cluster for the same partition. There is a sample class in the test directory to do this.
I then started the application with a MaxHeapSize of 256mb, then used curl to hit the events/stream endpoint:
As you can see 610M came back in 7 minutes. The whole time I had VisuamVM attached to the application and the coordinator and monitored the memory usage.
Here's the graph from the application:
The test was ran from 14:22 to 14:37. Even though we were
pumping through 610M of data through the application the heap was gittering between 50m and 200m, easily able to
reclaim the memory of the data we have streamed out.
For those new to Cassandra and other distributed databases this might not seem that spectacular, but I once wrote a rather large project to do what we can manage here in a few lines. Awesome work by the Apache Cassandra commitors and the DataStax Java driver team.