A few more Cassandra aggregates...
My last post was on UDAs in C* 2.2 beta. C*2.2 is now at RC1 so again everything in this post is subject to change. I'm running off 3.0 trunk so it is even more hairy. Anyway there are more built in UDAs now so let's take a look...
I am going to be using the schema from KillrWeather to illustrate the new functionality. KillrWeather is a cool project that uses C* for its storage and a combination of Spark batch and Spark Streaming to provide analytics on weather data.
Now C* hasn't previously supported aggregates but 2.2 changes all that, so let's see which parts of KillrWeather we can ditch the Spark and go pure C*.
The raw weather data schema:
Spark batch is used to populate the high low "materialised view" table:
The code from KillrWeather Spark batch:
There's a lot going on here as this code is from a fully fledged Akka based system. But essentially it is running a Spark batch job against a C* partition and then using the Spark StatsCounter to work out the max/min temperature etc. This is all done against the raw table, (not shown) the result is passed back to the requester and asynchronously saved to the C* daily_aggregate table.
Stand alone this would look something like:
Now let's do something crazy and see if we can do away with this extra table and use C* aggregates directly against the raw data table:

Because we have the year, month, as clusterting columns we can get the max/min/avg all from the raw table. This will perform nicely as it is within a C* partition, don't do this across partitions! We haven't even had to define our own UDFs/UDAs as max and mean are built in. I wanted to analyse how long this UDA was taking but it currently isn't in trace so I raised a jira.
The next thing KillrWeather does is keep this table up to date with Spark streaming:
Can we do that with built in UDAs? Uh huh!
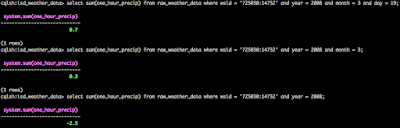
The data is a little weird as for one_hour_precip there are negative values, hence why it appears that we have less rain in a month than we do in a single day in that month.
We can also do things that don't include a partition key like get the max for all weather stations, but this will be slow / could cause OOM errors if you have a large table:

All the raw text for the queries are on my GitHub.
I am going to be using the schema from KillrWeather to illustrate the new functionality. KillrWeather is a cool project that uses C* for its storage and a combination of Spark batch and Spark Streaming to provide analytics on weather data.
Now C* hasn't previously supported aggregates but 2.2 changes all that, so let's see which parts of KillrWeather we can ditch the Spark and go pure C*.
The raw weather data schema:
Spark batch is used to populate the high low "materialised view" table:
The code from KillrWeather Spark batch:
There's a lot going on here as this code is from a fully fledged Akka based system. But essentially it is running a Spark batch job against a C* partition and then using the Spark StatsCounter to work out the max/min temperature etc. This is all done against the raw table, (not shown) the result is passed back to the requester and asynchronously saved to the C* daily_aggregate table.
Stand alone this would look something like:
Now let's do something crazy and see if we can do away with this extra table and use C* aggregates directly against the raw data table:

Because we have the year, month, as clusterting columns we can get the max/min/avg all from the raw table. This will perform nicely as it is within a C* partition, don't do this across partitions! We haven't even had to define our own UDFs/UDAs as max and mean are built in. I wanted to analyse how long this UDA was taking but it currently isn't in trace so I raised a jira.
The next thing KillrWeather does is keep this table up to date with Spark streaming:
Can we do that with built in UDAs? Uh huh!
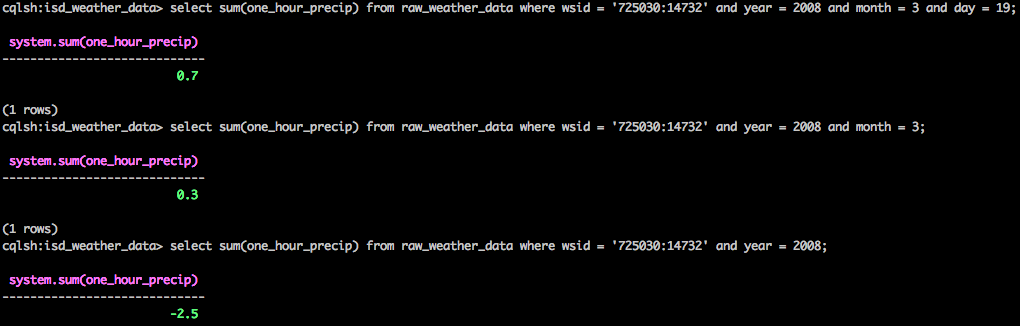
The data is a little weird as for one_hour_precip there are negative values, hence why it appears that we have less rain in a month than we do in a single day in that month.
We can also do things that don't include a partition key like get the max for all weather stations, but this will be slow / could cause OOM errors if you have a large table:
All the raw text for the queries are on my GitHub.