Cassandra 3.0 materialised views in action (pre-release)
Disclaimer: C* 3.0 is not released yet and all these examples are from a branch that hasn't even made it to trunk yet.
So this feature started off as "Global indexes", the final result is not a global index and I don't trust any claim of distributed indexes anyhow. If your data is spread across 200 machines, ad-hoc queries aren't a good idea reagardless of how you implement them as you will often end up going to all 200 machines.
Instead materialised views make a copy of your data partitioned a different way, which is basically what we've been doing manually in C* for years, this feature aims to remove the heavy lifting.
I'll use the same data model as the last article which is from the KillrWeather application. I will attempt to show use cases which we'd have previously used Spark or duplicated our data manually.
Recall the main data table:
This table assumes our queries are all going to be isolated to a weather station id (wsid) as it is the partition key. The KillrWeather application also has a table with information about each weather station:
I am going to denormalise by adding the columns from the weather_station table directly in the raw_weather_data table ending up with:
Now can we do some awesome things with materialised views? Of course we can!
So imagine you need to read the data not by weather station ID but by state_code. We'd normally have to write more code to duplicate the data manually. Not any more.

So this feature started off as "Global indexes", the final result is not a global index and I don't trust any claim of distributed indexes anyhow. If your data is spread across 200 machines, ad-hoc queries aren't a good idea reagardless of how you implement them as you will often end up going to all 200 machines.
Instead materialised views make a copy of your data partitioned a different way, which is basically what we've been doing manually in C* for years, this feature aims to remove the heavy lifting.
I'll use the same data model as the last article which is from the KillrWeather application. I will attempt to show use cases which we'd have previously used Spark or duplicated our data manually.
Recall the main data table:
This table assumes our queries are all going to be isolated to a weather station id (wsid) as it is the partition key. The KillrWeather application also has a table with information about each weather station:
I am going to denormalise by adding the columns from the weather_station table directly in the raw_weather_data table ending up with:
Now can we do some awesome things with materialised views? Of course we can!
So imagine you need to read the data not by weather station ID but by state_code. We'd normally have to write more code to duplicate the data manually. Not any more.
First let's insert some data, I've only inserted the primary key columns and one_hour_precip and I may have used UK
county names rather than states :)
We can of course query by weather id and time e.g

We can then create a view:
We've asked C* is to materialise select country_code from raw_weather_data
but with a different partition key, how awesome is that?? All of the original primary key columns and any columns in
your new primary key are automatically added and I've added country_code for no good reason.
With that we can query by state and year as well. I included year as I assumed that partitioning by state would lead to very large partitions in the view table.

With that we can query by state and year as well. I included year as I assumed that partitioning by state would lead to very large partitions in the view table.

Where as secondary indexes go to the original table, which will often result in a multi partition query (a C*
anti-pattern), a materialised view is copy of your data partitioned in a new way. This query will be as quick as if
you'd duplicated the data your self.
The big take away here is that YOU, the developer, decide the partitioning of the materialised view. This is an important point. There was talk of you only needing to specify a cardinality, e.g low, medium, high or unique and leave C* to decide the partitioning. Where as that would have appeared more user friendly it would be a new concept and a layer of abstraction when IMO it is critical all C* developers/ops understand the importance of partitioning and we already do it every day for tables. You can now use all that knowledge you already have to design good primary keys for views.
I'll use the term "original primary key" to refer to the table we're creating a materialised view on and MV primary key for our new view.
The big take away here is that YOU, the developer, decide the partitioning of the materialised view. This is an important point. There was talk of you only needing to specify a cardinality, e.g low, medium, high or unique and leave C* to decide the partitioning. Where as that would have appeared more user friendly it would be a new concept and a layer of abstraction when IMO it is critical all C* developers/ops understand the importance of partitioning and we already do it every day for tables. You can now use all that knowledge you already have to design good primary keys for views.
The fine print
I'll use the term "original primary key" to refer to the table we're creating a materialised view on and MV primary key for our new view.
- You can include any part of the original primary key in your MV primary key and a single column that was not part of your original primary key
- Any part of the original primary key you don't use will be added to the end of your clustering columns to keep it a one to one mapping
- If the part of your primary key is NULL then it won't appear in the materialised view
- There is overhead added to the write path for each materialised view
Original primary key: PRIMARY KEY ((wsid), year, month, day, hour)
MV primary key: PRIMARY KEY ((state_code, year), one_hour_precip)
Conclusion: No, this is actually the example above and it does not work as we tried to include two columns
that weren't part of the original primary key. I updated the original primary key to: PRIMARY KEY ((wsid), year, month, day, hour, state_code) and
then it worked.
Original primary key: PRIMARY KEY ((wsid), year, month, day, hour)
MV primary key: PRIMARY KEY ((state_code, year))
Conclusion: Yes - only one new column in the primary key: state_code
Here are some of the other questions that came up:
- Is historic data put into the view on creation? Yes
- Can the number of fields be limited in the new view? Yes - in the select clause
- Is the view written to synchronously or asynchronously on the write path? Very subject to change! It's complicated! The view mutations are put in the batch log and sent out before the write, the write can succeed before all the view replicas have acknowledged the update but the batch log won't be cleared until a majority of them have responded. See the diagram in this article.
- Are deletes reflected? Yes, yes they are!
- Are updated reflected? Yes, yes they are!
- What happens if I delete a table? The views are deleted
- Can I update data via the view? No
- What is the overhead? TBD, though it will be similar to using a logged batch if you had duplicated manually.
- Will Patrick Mcfadin have to change all his data modelling talks? Well at least some of them
Combining aggregates and MVs? Oh yes
You can't use aggregates in the select clause for creating the materialised view but you can use them when querying
the materialised view. So we can now answer questions like what is the total precipitation for a given year for a
given state:

We can change our view to include the month in its key and do the same for monthly:
And then we can do:
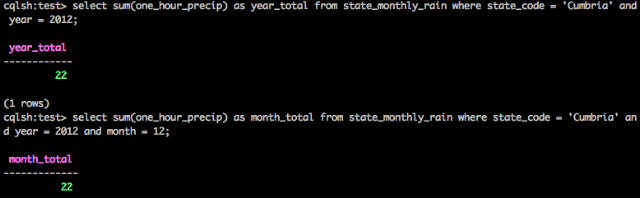
Though my data had all the rain in one month :)

We can change our view to include the month in its key and do the same for monthly:
And then we can do:
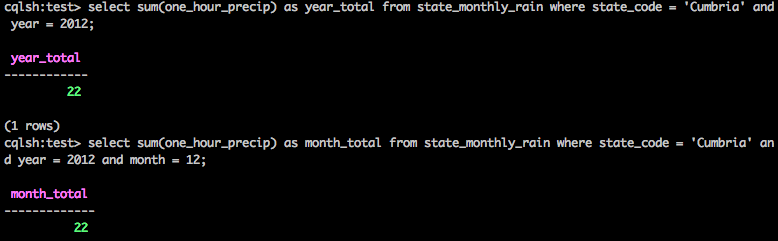
Though my data had all the rain in one month :)
Conclusion
This feature changes no key concepts for C* data modelling it simply makes the implementation of the intended data
model vastly easier. If you have data set that doesn't fit on a single server you're still denormalising and
duplicating for performance and scalability, C* will just do a huge amount of it for you in 3.0.