Cassandra anti-pattern: Distributed joins / multi-partition queries
There’s a reason when you shard a relational databases you are then prevented from doing joins. Not only will they be slow and fraught with consistency issues but they are also terrible for availability. For that reason Cassandra doesn’t even let you join as every join would be a distributed join in Cassandra (you have more that one node right?).
This often leads developers to do the join client side in code. Most of the time this is a bad idea, but let’s understand just how bad it can be.
Let’s take an example where we want to store what our customers are up to, here’s what we want to store:
- Customer event
- customer_id e.g ChrisBatey
- staff_id e.g Charlie
- event_type e.g login, logout, add_to_basket, remove_from_basket
- time
- Store
- name
- store_type e.g Website, PhoneApp, Phone, Retail
- location
We want to be able to do retrieve the last N events, time slices and later we’ll do analytics on the whole table. Let’s get modelling! We start off with this:
This leads us to query the customer events table, then if we want to retrieve the store or staff information we need to do another query. This can be visualised as following (query issued at QUORUM with a RF of 3):
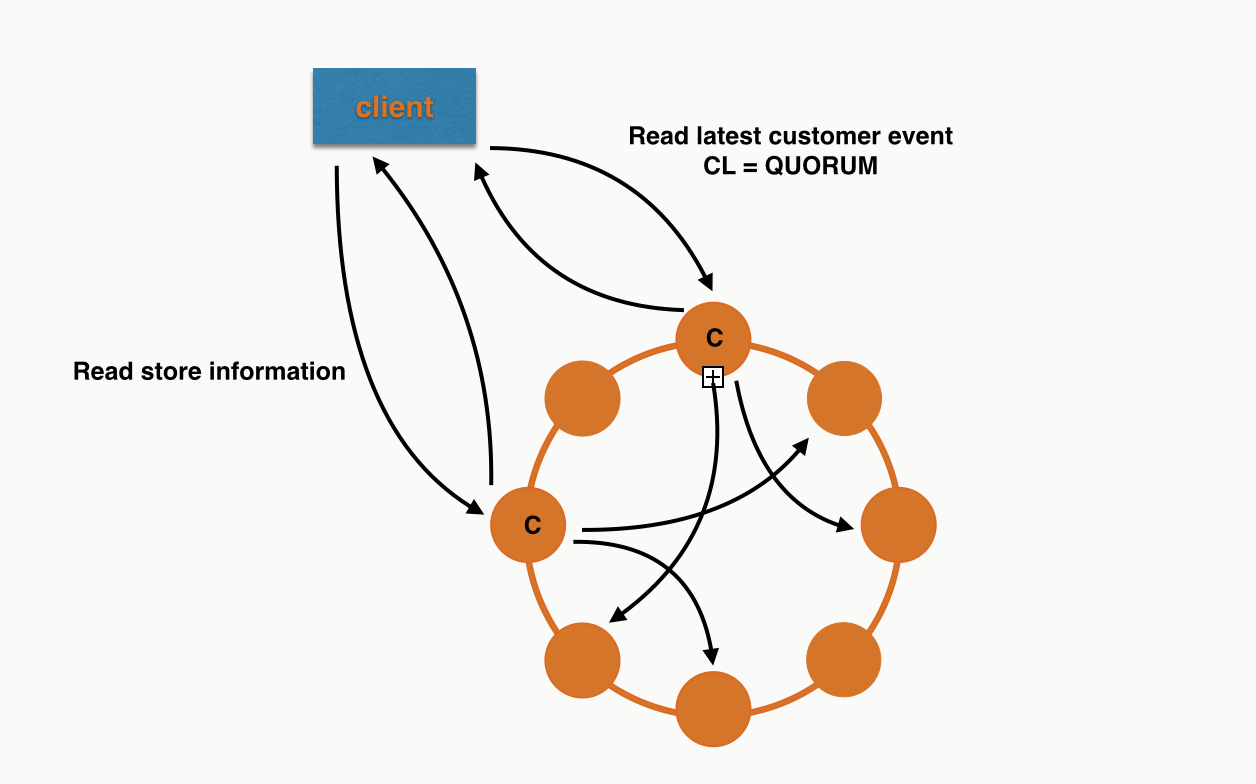
For the second query we’ve used a different coordinator and have gone to different nodes to retrieve the data as it is in a different partition.
This is what you’d call a one to one relationship for a single query but in reality it is a many to one as no doubt many customer events reference the same store. By doing a client side join we are relying on a lot of nodes being up for both our queries to succeed.
We’d be doing a similar thing for staff information. But Let’s make things worse by changing the staff relationship so that we can associate multiple staff members with a single customer event.
The subtle difference here is that the staff column is now a set. This will lead to query patterns like:
This looks good right? We’re querying by partition id in the staff table. However it isn’t as innocent as it looks. What we’re asking the coordinator do do now is query for multiple partitions, meaning it will only succeed if there are enough replica up for them all. Let’s use trace to see how this would work in a 6 node cluster:
Here I've span up a 6 node cluster on my machine (I have a lot of RAM) with the IPs 127.0.0.(1-6).
We'll now insert a few rows in the staff table:
Now lets run a query with consistency level ONE with tracing on:
The coordinator has had to go to replicas for all the partitions. For this query 127.0.0.1 acted as coordinator and the data was retrieved from 127.0.0.3, 127.0.0.5, 127.0.0.6. So 4 out of 6 nodes needed to be behaving for our query to succeed. If we add more partitions you can see how quickly we’d end up in a situation where all nodes in the cluster need to be up!
Let’s make things even worse by upping the consistency to QUORUM:
Here 127.0.0.1 was the coordinator again, and this time 127.0.0.2, 127.0.0.3, 127.0.0.4, 127.0.0.5 were all required, we’re now at 5/6 nodes required to satisfy what looks like a single query.
This makes the query vastly more likely to ReadTimeout.
It also gives the coordinator much more work to do as it is waiting for responses from many nodes for a longer time.
So how do we fix it? We denormalise of course!
Essentially we've replaced tables with user defined types.
Now when we query for a customer event we already have all the information. We’re giving coordinators less work to do and each query we do only requires the consistency’s worth of nodes to be available.
Can I ever break this rule?
In my experience there are two times you could consider breaking the no-join rule.
- The data you’re denormalising is so large that it costs too much
- The table like store or staff is so small it is okay to keep it in memory
The other time you may want to avoid denormalisation is when a table like staff or store is so small it is feasible to keep a copy of it in memory in all your application nodes. You then have the problem about how often to refresh it from Cassandra etc, but this isn't any worse than denormalised data where you typically won’t go back and update information like the store location.
Conclusion
To get the most out of Cassandra you need to retrieve all of the data you want for a particular query from a single partition. Anytime you don’t you are essentially doing a distributed join, this could be explicitly in your application of asking Cassandra to go to multiple partitions with an IN query. These types of queries should be avoided as often as possible. Like with all good rules there are exceptions but most users of Cassandra should never have to use them.
Any questions feel free to ping me on twitter @chbatey